Chapters
Natural Language Processing

Weaving NLP Terminologies Together
Basics
Natural Language Processing: Natural Language Processing, NLP for short, is the subfield of linguistics, computer science, and artificial intelligence, that concerns with the automated translation of Human Language, for computers to process and analyze large amounts of natural language data
Data Preprocessing: Data preprocessing is a process of preparing the raw data and making it suitable for a machine learning model
Tokenization: An important step in textual data preprocessing, tokenization is transformation of larger chunk of string, into smaller chunks, i.e. tokens
Sentimental: Having or arousing feelings def
Stop Words: Those words which are eliminated from the data, which contribute little to overall
determination of sentimental-value, as known as Stop Word. E.g. And, Because, Very, The, An, etc.

Morphmeme: In linguistic study of language, a Morpheme is A morpheme is the smallest part of a word
that has grammatical function or meaning, e.g.
 Credits: colostate.edu
Credits: colostate.edu
Free Morpheme: A Morpheme which can which can stand alone as meaniungful word, is called as Free
Morpheme, e.g.
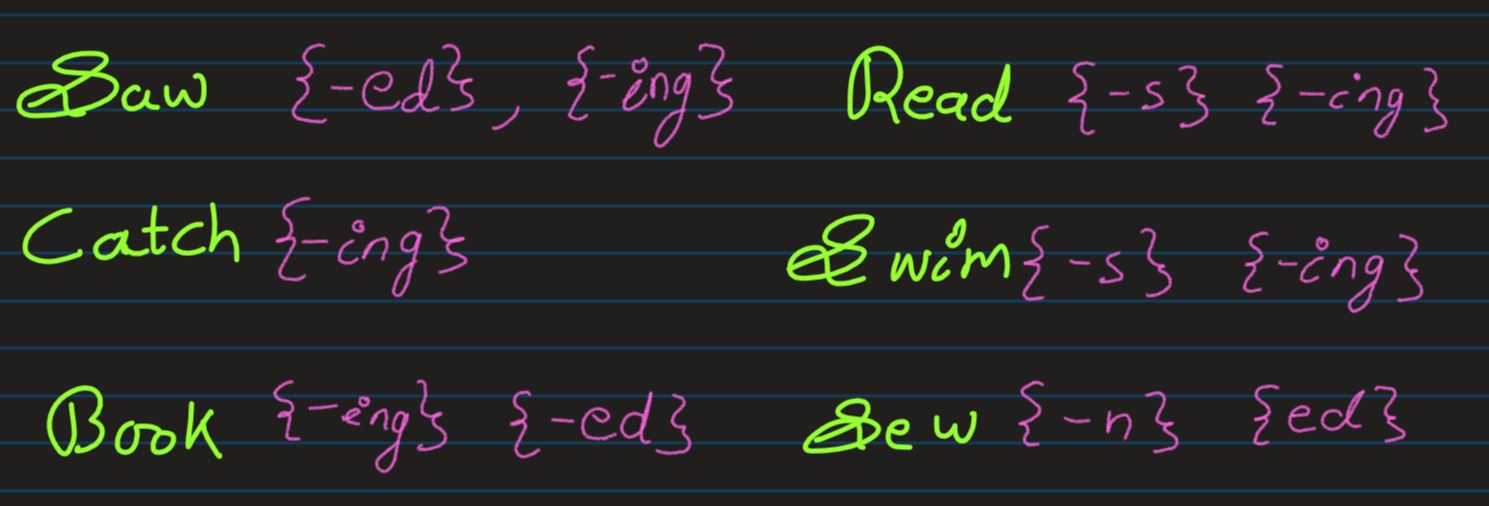
Root Word: A root is the simplest form attainable by separating a word into its component parts
Stem: The body of a word, to which the "terminations" are attached, is called the stem
Stemming: Stemming is the process of eliminating affixes (suffixed, prefixes, infixes, circumfixes) from a word in order to obtain a word stem
Lemma: Lemma is base or dictionary form of a word
Lemmatization: Lemmatization is related to stemming, differing in that lemmatization is able to
capture canonical forms based on a word's lemma
e.g. words like break, breaks, broke, broken and breaking are all originated from the same source (lexeme),
i.e. "break". And "break" is thier lemma, by which they are all indexed
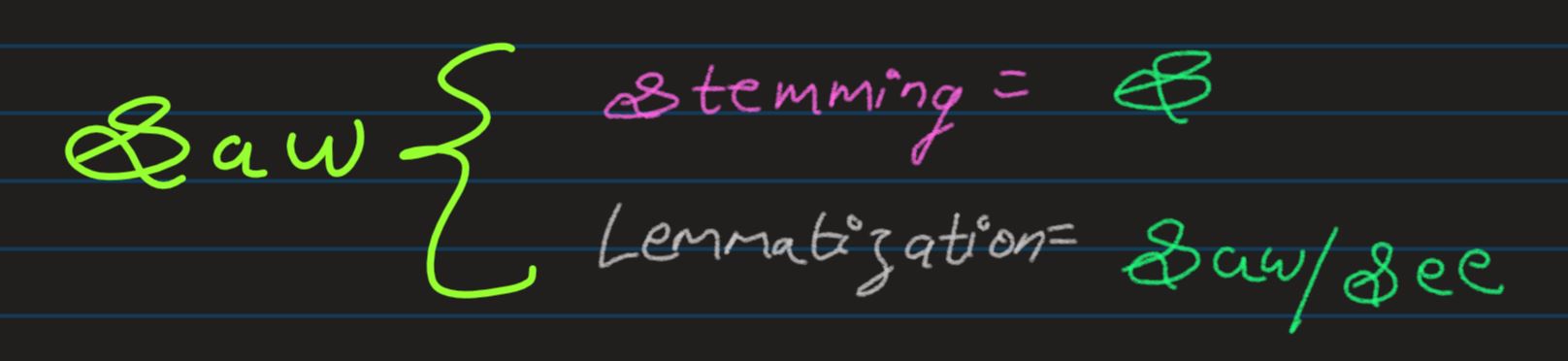 Credits: nlp.stanford.edu
Credits: nlp.stanford.edu
Corpus: A collection of texts is called as Corpus (plural: Corpora)